





MODIFIED ON: November 29, 2022 / ALIGNMINDS TECHNOLOGIES / 0 COMMENTS

Gartner defines edge computing as a distributed computing topology where information processing is located close to the edge where things and people produce or consume that information.
The birth of edge computing can be traced back to the 1990s when content distribution networks were created to serve web and video content from edge servers close to users. Later, edge computing evolved into an advanced version that hosts applications and application components such as shopping carts, ad insertion engines, dealer locators and real-time data aggregators.
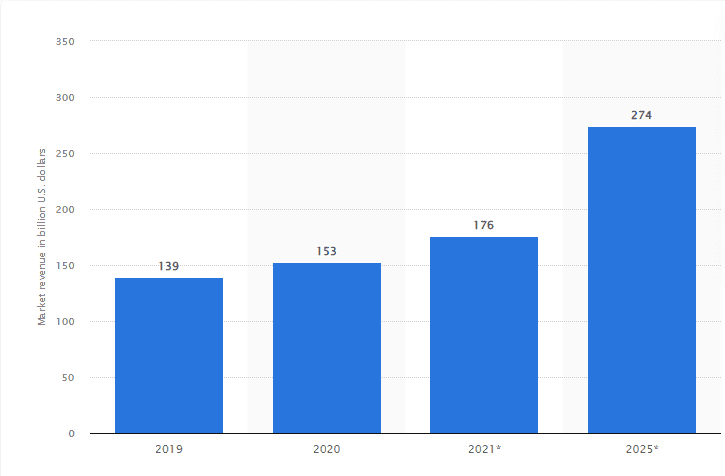
Edge computing market revenue worldwide from 2019 to 2025(in billion U.S. dollars) Source: Statista
The number of papers related to edge computing on Google Scholar was only 720 in 2015. However, it has grown to more than 25,000 in 2020. The number of edge patent filings done as of 2020 is 6,418. This is a hundred times more than the number of patents filed related to edge computing in 2015.
While the edge computing market was valued at 139 billion US dollars in 2019, it is expected to reach 274 billion US Dollars in value by 2025.
Apart from these data and figures, if we investigate the real world, the word “edge computing” is becoming familiar across industries, day by day.
So, what’s the deal with edge computing? Why more and more companies are adopting it and becoming an advocate for this technology?
What is edge computing?
Cloudflare defines edge computing as
“Edge computing is a networking philosophy focused on bringing computing as close to the source of data as possible in order to reduce latency and bandwidth use. In simpler terms, edge computing means running fewer processes in the cloud and moving those processes to local places, such as on a user’s computer, an IoT device, or an edge server. “
From this definition, it is clear that edge computing is a distributed computing principle applied by companies to reduce delay in information processing and bandwidth usage by moving computing closer to the source of information.
Since the computing is executed as close as possible to the users, there is minimal long-distance communication between a client and the server. As a result, the users will have a faster and more secure experience when using technology-based services and the service providers will have the benefits of providing the best-in-class user experience.
How does edge computing work?
Traditionally, enterprise computing was done by moving data that is produced at the user’s devices via the internet to enterprise servers, then it is stored and worked upon, and the results were sent back to the user’s device. Client-server computing was the most proven and time-tested approach implemented by most organisations.
However, ever since the internet and digital revolution, the volume of data produced by consumers and shared with enterprises skyrocketed. Sending, storing, and computing such a large volume of data at a centre infrastructure became a herculean task. Also, sending and receiving so much data put a toll on the internet. There was frequent congestion, latency issues even downtime that affected the services.
So, the industry came up with an idea of a decentralized system in which the storage and computing are done closer to where the information is produced. Since the computing is done at this closer point, called “the edge”, this approach is known as “edge computing”.
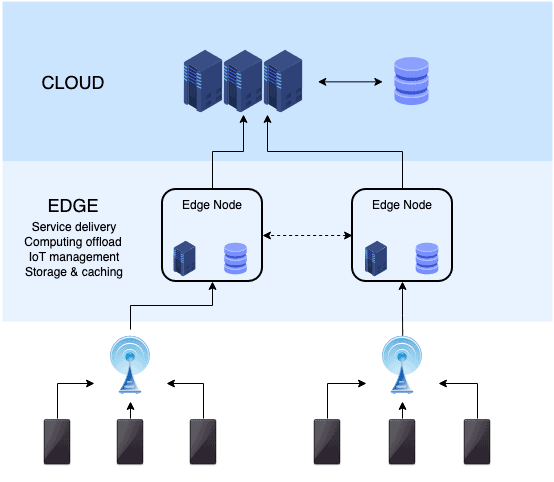
Image credit: Wikipedia commons
Edge nodes or Edge servers collect and process data locally. Depending on the business model and architecture, sometimes the results of the process are sent to the principal server that is deployed in the cloud.
To better understand how edge computing works, here are a few use cases for you.
Transportation
Self-driven vehicles are replacing manual-driven vehicles at a faster rate. They are widely used for cargo movements and courier services. Such autonomous vehicles function by aggregating a large volume of data related to their location, physical condition, road condition, climate condition, traffic condition, speed and movements of other vehicles close by. It is by gathering and analysing such data in real-time that the vehicle is able to reach its destination without any accident or shortcomings. To facilitates this “auto-piloting”, onboard computing is very much required as a single self-driven vehicle produces anywhere between 5 TB to 20 TB of data in a day.
Network routing
Latency has a significant role in internet traffic. To ensure the quality of the network, the traffic must be routed via the most reliable and low latency path. Edge computing can help with optimizing network routes by regularly measuring traffic conditions across the internet and choosing the best path for each user’s traffic.
Healthcare
Healthcare has technologised rapidly in recent years. There are countless pieces of equipment that make use of the latest technologies to diagnose and monitor the health of a patent. Such types of equipment collect and process large volumes of data, regularly for a longer period of time. With the help of edge computing and machine learning these data can be used for finding abnormalities and delivering proper treatment at the right time.
Retail
The benefit of implementing edge computing in the retail sphere is manyfold. It can be used for surveillance, stock tracking and refilling, real-time sales monitoring, and analysis, aggregating, sales and customer information, loyalty programmes based on sales data, item procurements etc.
Manufacturing
A product must go through many stages before its ready for sending to the market. These stages include product design, prototyping, production, quality checks, packaging, and branding. By implementing edge computing, manufacturers are able to monitor these activities in real-time and at a large scale and it also enables them to reduce resource wastage and find loopholes in the existing process. Together with machine learning, edge computing helps manufacturers collect and analyse data in real-time. Making the right decision at the right time has become easier for them.
Benefits of edge computing
Speed
Since data is produced and processed at the same point, computing became a lot faster. There is no need to send and receive large chunks of data and there is little to no uncertainty of computing demands. Due to this increased responsiveness, edge computing is better than traditional and cloud computing in so many cases such as IoT, autonomous driving, healthcare, public safety, surveillance, augmented reality etc.
The healthcare industry has already recognized the benefit of edge computing.
Reliability
The distributed topology ensures that reliability is not a concern when it comes to edge computing. Because the data is produced and processed at the edge, and multiple edge nodes are used in the system, failure in one node does not affect the remaining ones. Also, since there is a low dependency on the central cloud server, any disruption in the connectivity between the cloud and edge node will not affect the overall performance. In fact, once the connection is restored, the data can be securely synchronized between the nodes and server.
Efficiency
Since computing is executed at the edge, edge computing offers a sophisticated environment that is fit for the usage of advanced analytical tools, artificial intelligence, and machine learning. We have already seen how this can help certain industries like transportation and healthcare.
The opportunity to use powerful analytical tools also helps the system to optimize itself. The system can regularly monitor the user demands and determine where to execute the computing depending on how resource-intensive the task is. For example, if the edge node has the required capacity, it can execute the task and send back the results to the client device saving up bandwidth, resources, and time. If the task requires additional resources, it can be assigned to the central server, where most resource-intensive but rare occurrence tasks are executed.
Scalability
A distributed system is easier to scale than a traditional one. New nodes can be set up to meet the growing demands and any addition or removal of nodes will not affect the system as a whole. Also, each node can be customized according to demands that are specific to the area it serves.
Privacy and security
Edge computing makes use of special encryption mechanisms to protect data that may travel between client and nodes, nodes and nodes and nodes and server. Using a decentralized trust model, the communication between each node is evaluated and whitelisted. Since edge computing emphasises producing, gathering, and processing data at a single point, data is handled in a better way in terms of security and privacy. For example, a node that is situated in a particular geography can be governed by the local law and the condition of local infrastructure and vulnerabilities can also be taken into consideration while setting up the security measures.
Is edge computing and IoT the same?
It is a common misconception that edge computing and IoT are the same. In reality, Internet of Things (IoT) is a use case of edge computing.
IoT makes use of cloud servers for data storage and computing. It means that IoT totally depends on the internet for connectivity. It also means that IoT implementations are centralized and usually intended for specific purposes only.
However, edge computing is decentralized by design, and it can be implemented independently of the internet since data can be produced, collected, and processed at a single point. An edge computing system can also be generic in nature and the data and processes can be heterogeneous.
In short, IoT can be implemented as part of edge computing. However, both are vastly different.
Edge vs cloud vs fog computing
It is common to compare the new technology with existing ones to find out whether it is justifiable to adopt it for your business. The case of edge computing is not exceptional in this matter. Organisations are already used to cloud and fog computing. There should be apparent incentives for them to adopt the new kid in the block. So, let us discuss how these three are different from each other and what they bring to the table.

Edge computing
Edge computing is the deployment of computing and storage resources closer to where the data is produced or consumed. For example, a retail mall with an indoor traffic system can use edge computing to collect and process traffic data in real-time to facilitate its smooth functioning. If it is a chain business, data can be sent to a centralized data centre for human review. However, if the amount of data collected and processed exceeds the computing and storage capacity, the system will fail until the capabilities are improved.
Cloud computing
Cloud computing is the distributed deployment of computational resources and data storage over multiple locations. Since computing is available on-demand, cloud computing is highly scalably and affordable at the same time. Since it is a distributed system, cloud computing offers better storage and retrievability of data and there is least to nil concern about data being lost forever.
However, each cloud server can still be far away from end-users. Data is processing at these far away points and the system depends on the internet to share the data between client and server. In other words, cloud computing is nothing but traditional computing implemented in a distributed architecture that depends on the internet. It consumes bandwidth, can be affected by latency and even overwhelmed by a sudden surge in demands if not configured with the right anticipation.
Fog computing
Fog computing or fogging is an improvised version of edge computing. Sometimes, “the edge” become so large that implementing a strict edge computing system will be detrimental to the actual plan. For example, smart cities are producing a large volume of data every minute. These data are heterogeneous in nature and used for different purposes. However, the objective of the whole implementation could be based on a few principles. Setting up several nodes to cover the whole city will not be practical and it will also affect the objective of the whole system. So, such a system makes use of a fog layer that consists of fog nodes. These fog nodes act as a backend to the edge nodes and add additional computing power to the whole system. Fog computing is the combination of cloud and edge computing and aims to mitigate the weaknesses of both.

Conclusion
Edge computing has opened up so many untapped opportunities and several industries have already started leveraging its advantages. However, its true potential is still unachievable due to the lack of compact devices with enough computing power and software that can handle a limitless number of edge devices. Improvised versions of edge computing such as fog computing may be a step in the right direction.
Are you looking for a renowned technology partner to develop a next-generation edge computing solution? Contact our team of experts for a free consultation.
Leave a reply
Your email address will not be published.
-
Recent Posts
- The Ultimate 4-Step Guide to Modernizing Your Applications
- The 12 Most Popular Computer Vision Tools in 2024
- How MLOps is Transforming Businesses in 2024
- The Ultimate Guide to Product Engineering Services for Businesses
- 5 Top Use Cases of Computer Vision in the Hospitality Industry
-
Categories
- MVP Development (5)
- AlignMinds (55)
- Operating Systems (1)
- Android POS (3)
- Application Hosting (1)
- Artificial Intelligence (23)
- Big Data (2)
- Blockchain (1)
- Cloud Application Development (7)
- Software Development (29)
- Software Testing (9)
- Strategy & User Experience Design (4)
- Web Application Development (23)
- Cyber Security (6)
- Outsourcing (7)
- Programming Languages (3)
- DevOps (5)
- Software Designing (6)
- How to Code (4)
- Internet of Things (1)
- Machine Learning (2)
- Mobile App Marketing (4)
- Mobile Application Development (18)
- Mobile Applications (5)